Cómo elegir un tipo de gráfico en función de las preguntas de investigación
 Imagen hecha por mí con el paquete {aRtsy}
Imagen hecha por mí con el paquete {aRtsy}Los gráficos o visualizaciones son parte ineludible de cualquier artículo científico o reporte de trabajo. Permiten organizar la información de forma visual y así lograr un procesamiento más holístico. Sin embargo, muchas veces ponemos el carro delante del caballo y nos mandamos a hacer un gráfico solo porque nos gusta o porque está de moda (o peor: porque alguien más nos dijo que lo hagamos), sin tener en cuenta si ese tipo de gráfico es el ideal para lo que queremos mostrar.
En este post vamos a analizar distintas preguntas de investigación posibles a partir de una base de datos, y qué gráficos serían los ideales para visualizar esa información. Si bien habrá código, no es un post técnico; eso lo dejamos para otro momento.
El dataset
Vamos a trabajar con el dataset Extramarital affairs, que es una investigación realizada en 1969, que pueden encontrar en Kaggle. Una vez que tenemos cargado el dataset, lo primero que hacemos es inspeccionar las variables:
library(tidyverse)
glimpse(affairs)## Rows: 601
## Columns: 10
## $ ...1 <dbl> 4, 5, 11, 16, 23, 29, 44, 45, 47, 49, 50, 55, 64, 80, 86…
## $ affairs <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ gender <chr> "male", "female", "female", "male", "male", "female", "f…
## $ age <dbl> 37, 27, 32, 57, 22, 32, 22, 57, 32, 22, 37, 27, 47, 22, …
## $ yearsmarried <dbl> 10.00, 4.00, 15.00, 15.00, 0.75, 1.50, 0.75, 15.00, 15.0…
## $ children <chr> "no", "no", "yes", "yes", "no", "no", "no", "yes", "yes"…
## $ religiousness <dbl> 3, 4, 1, 5, 2, 2, 2, 2, 4, 4, 2, 4, 5, 2, 4, 1, 2, 3, 2,…
## $ education <dbl> 18, 14, 12, 18, 17, 17, 12, 14, 16, 14, 20, 18, 17, 17, …
## $ occupation <dbl> 7, 6, 1, 6, 6, 5, 1, 4, 1, 4, 7, 6, 6, 5, 5, 5, 4, 5, 5,…
## $ rating <dbl> 4, 4, 4, 5, 3, 5, 3, 4, 2, 5, 2, 4, 4, 4, 4, 5, 3, 4, 5,…Vemos entonces que tenemos una serie de variables numéricas y otras categóricas (género e hijos). Sin embargo, dentro de las numéricas tenemos algunas que son continuas (cantidad de affairs) y muchas otras que son ordinales, en el sentido de que representan sectores o bloques de valores. Va a ser muy importante tener en cuenta esto para no correr el riesgo de identificar por ejemplo la variable edad como continua.
Las preguntas
Existen tantas preguntas de investigación posibles como investigadores o datasets existen en el mundo. Una forma de organizar las preguntas puede ser la cantidad de variables que nos interesa analizar: entonces, podemos empezar por ejemplo preguntándonos cuántas personas tuvieron affairs y cuántas no, y para eso podemos hacer un gráfico de barras a partir de la variable affairs. Al mirar el dataset, vemos que esa variable, en verdad, responde cuántos affairs tuvieron las personas, es decir, no es una variable dicotómica sí/no. Entonces, nuestra pregunta original puede desprenderse en dos: ¿cuántas personas tuvieron affairs y cuántas no? y ¿cuántos affairs tuvieron las personas? Bien, manos a la obra.
Pregunta 1: ¿cuántas personas tuvieron affairs y cuántas no?
Para poder responder esta pregunta, tenemos que crear una nueva columna que sea dicotómica, con dos valores: “sí” y “no”.
affairs <- affairs %>%
mutate(affairs_dic = ifelse(affairs == 0, "no", "si"))Ahora podemos realizar nuestro gráfico:
ggplot(affairs, aes(x = affairs_dic))+
geom_bar()
Tenemos entonces nuestro primer gráfico que muestra que alrededor de 450 personas no tuvieron affairs, mientras que alrededor de 150 sí. Yo voy a dejar el gráfico así como está, pero les propongo algunas ideas para mejorarlo y de paso practicar su conocimiento de ggplot2:
Agregar título, epígrafe.
Cambiar los nombres de los ejes X e Y, y el texto de los valores para que quede con mayúscula y con tilde en la “í”.
Agregar color a las barras (y que cada tipo de respuesta sea un color distinto).
Agregar en cada barra un número con el valor exacto.
Pregunta 2: ¿cuántos affairs tuvieron las personas?
Esta pregunta tiene muchas formas distintas de ser respondida: podemos mirar las cantidades totales o podemos hacer promedios. Para hacer cantidades totales, podemos hacer un histograma:
ggplot(affairs, aes(x = affairs))+
geom_histogram()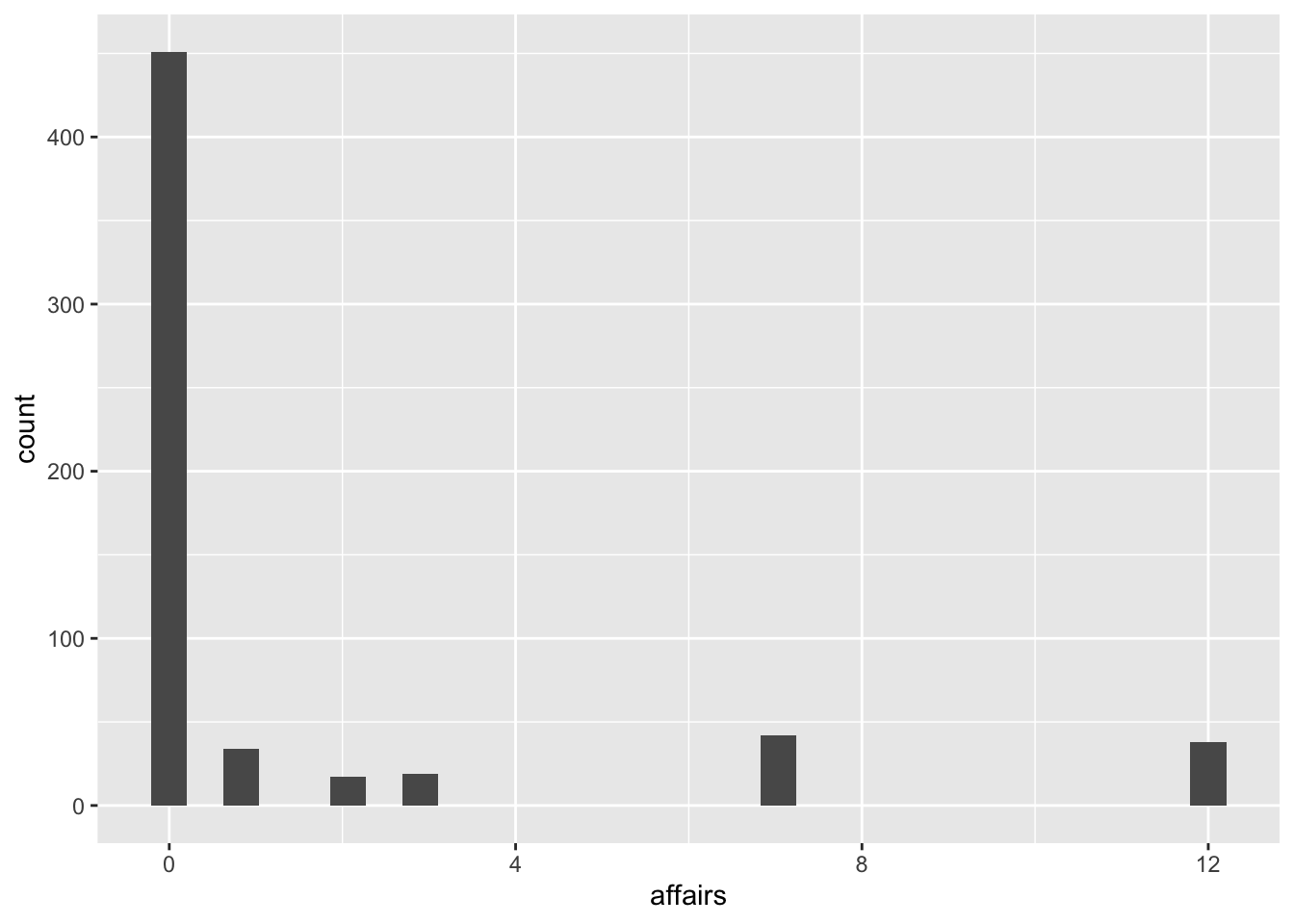
No es un gráfico muy agradable visualmente, pero nos permite ver que la amplísima mayoría de las personas tuvieron 0 affairs (algo que habíamos visto en el gráfico anterior), luego la mayoría de las personas tuvieron menos de 5 affairs, y luego hay algunos casos aislados que han tenido 6 y 12 affairs. Podríamos achicar la brecha en la cantidad de affairs modificando el tamaño de las barras:
ggplot(affairs, aes(x = affairs))+
geom_histogram(binwidth = 3)
La decisión sobre el ancho de las barras también es una decisión metodológica: ¿es lo mismo, en términos de la investigación, una persona que ha tenido 0 affairs y otra que ha tenido 1 o 2? Si la investigación fuera, por ejemplo, sobre fidelidad en el matrimonio, podríamos decir que no es lo mismo, pero si la investigación fuera sobre compulsiones o sobre adicción al sexo, tal vez no serían situaciones tan distintas (frente a quienes han tenido 6 o 12 affairs).
Para este gráfico, las cuestiones estéticas a mejorar son las mismas que para el gráfico anterior: el color, las etiquetas de los ejes, los nombres de las variables, las cantidades.
Estos dos gráficos, el de barras y el histograma, nos sirven para analizar una sola variable en función de sus cantidades. Pero tal vez nuestra investigación tiene que ver con identificar si hay diferencias en la cantidad de affairs que tienen los hombres y las mujeres; en ese caso, empezamos ya a cruzar dos variables.
Pregunta 3: ¿hay diferencias en la cantidad de affairs que tuvieron los hombres y las mujeres?
Esta pregunta tiene dos formas de respuesta: podemos pensar las cantidades totales o podemos pensar un promedio por género. Cada alternativa tiene su ventaja y su desventaja. Si hacemos las cantidades totales, nos encontramos con que este dataset tiene 315 respuestas de mujeres y 286 respuestas de hombres. Por lo tanto, las cantidades totales pueden ser engañosas: puede resultar que el número de affairs de mujeres sea mucho más alto que el de hombres solo por ser una mayor cantidad de sujetos.
Podemos resolver este problema haciendo un histograma, pero separando las barras por género con un color distinto:
ggplot(affairs, aes(x = affairs, fill = gender))+
geom_histogram(binwidth = 2, position = "identity", alpha = .6)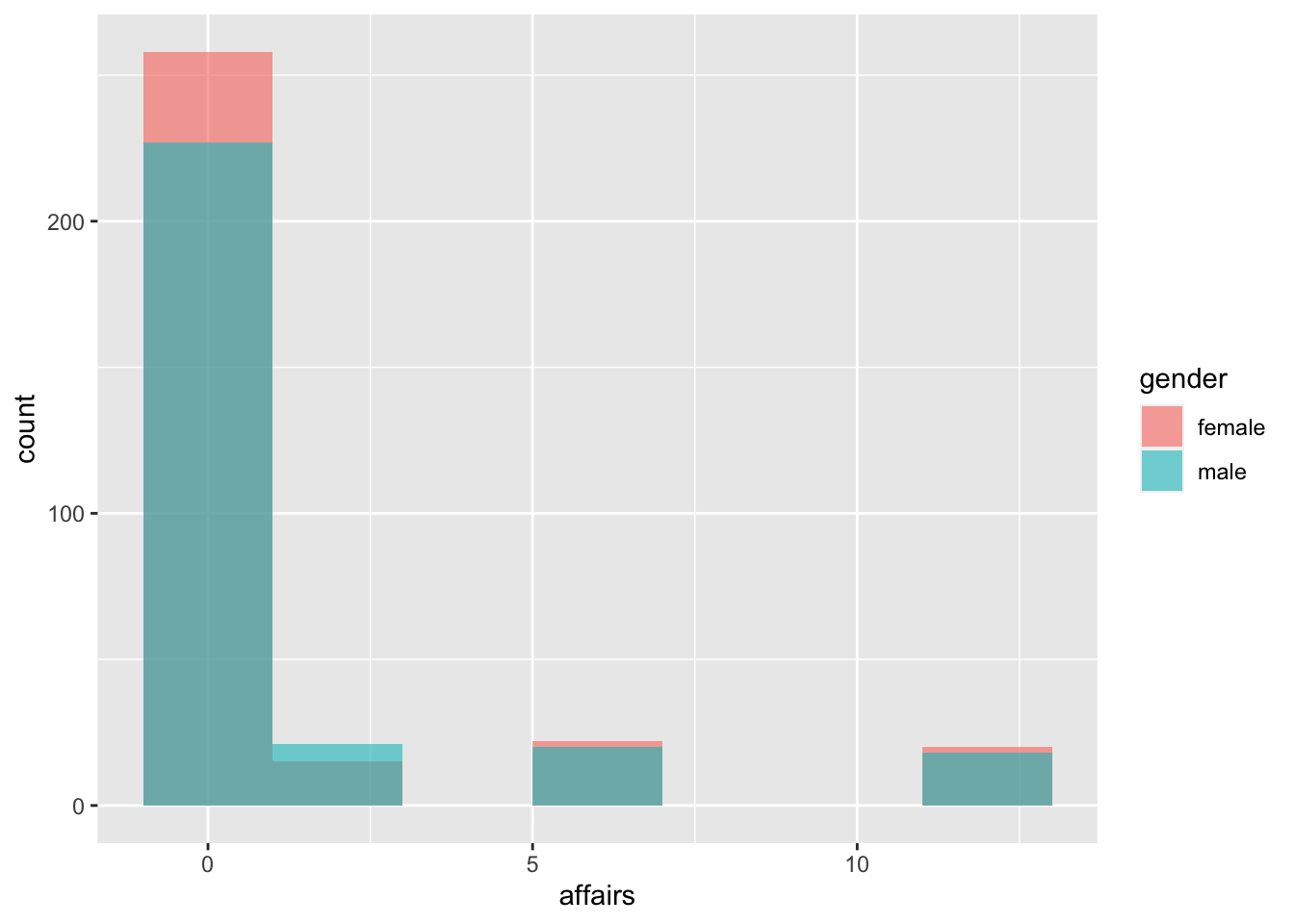
No es el gráfico más lindo del mundo (y tampoco el más informativo), pero hay varias cosas importantes. La primera diferencia con el histograma anterior es que se identifica un color con un género (fill = gender); la segunda es que se permite que haya superposición (position = "identity) y la tercera es que se especifica un grado importante de transparencia para poder ver esa superposición (alpha = .6). Podemos ver entonces que hay más mujers que hombres que tuvieron 0-1 affairs, un poco más de hombres que tuvieron entre 2 y 3, un poco más de mujeres que tuvieron 5-6 y también alrededor de 12. Sin embargo, recordemos que hay muchas más respuestas de mujeres que de hombres, por lo cual necesitamos saber si esa diferencia es proporcional o no. Acá es donde entra a la cancha la posibilidad de mirar las medias.
ggplot(affairs, aes(x = gender, y = affairs))+
geom_point(stat = "summary", fun = "mean")+
stat_summary(fun.data = "mean_se", geom = "errorbar",
width = .2)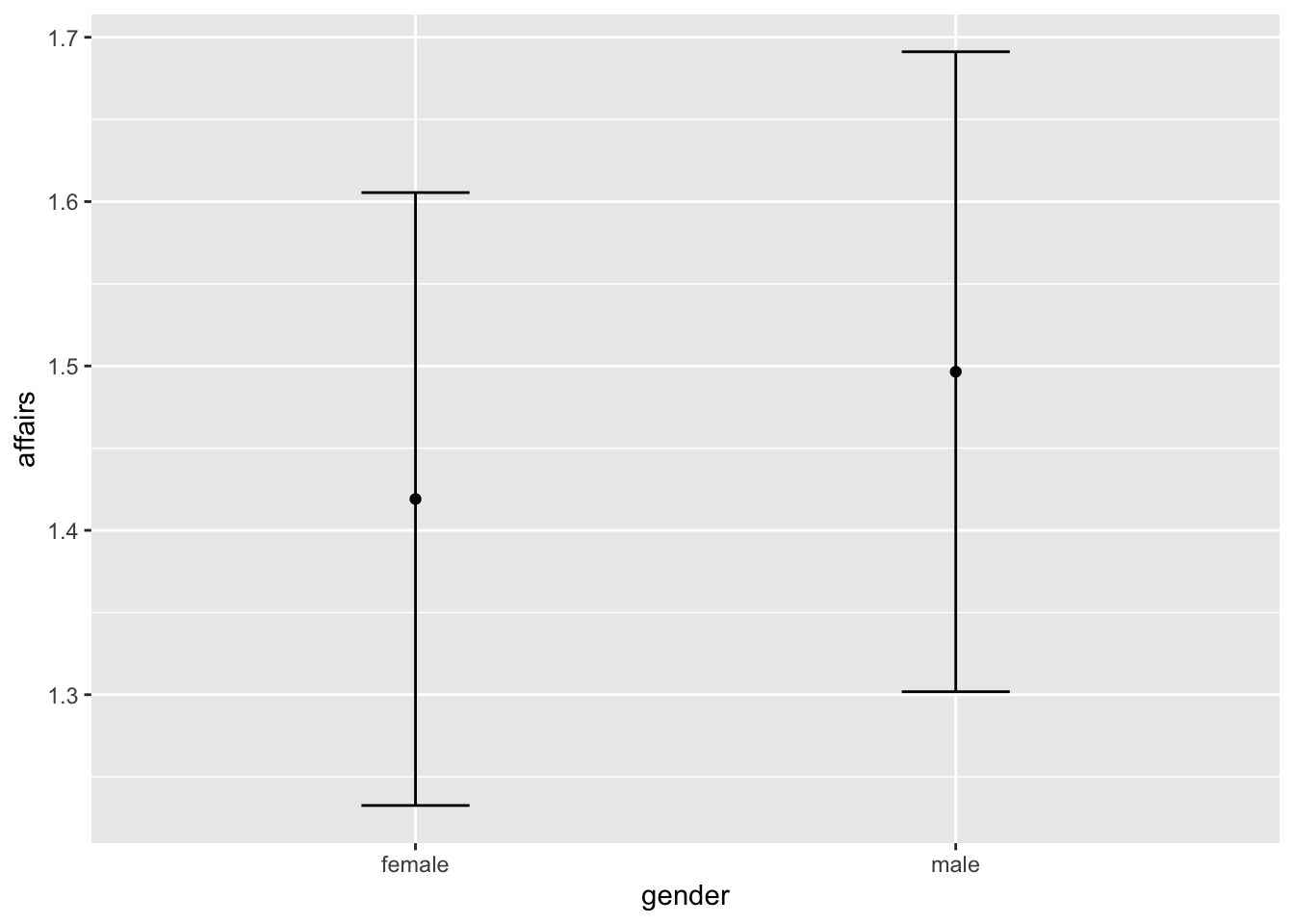
Bueno, acá tenemos un poco más de información: los hombres tienen en promedio 1.5 affairs, mientras que las mujeres tienen un poco más de 1.4. Ambos grupos, de todos modos, tienen una amplísima variabilidad. Esto también lo podemos ver con otro gráfico, el boxplot:
ggplot(affairs, aes(x = gender, y = affairs))+
geom_boxplot()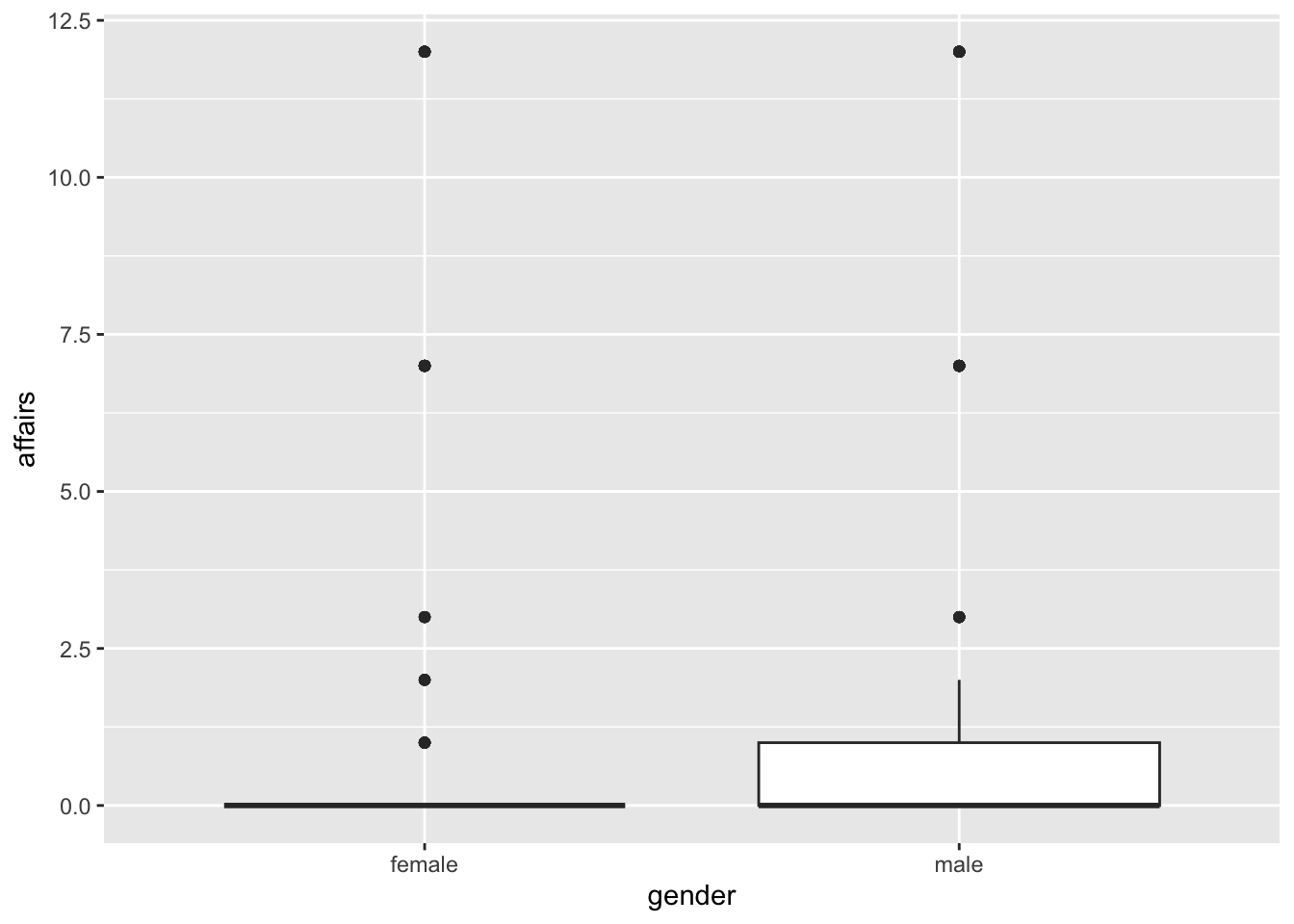
Parece que estuviera mal hecho el gráfico, ¿no? Pero la verdad es que está bien. El problema es que el boxplot analiza principalmente la mediana de los datos y cómo se distribuyen alrededor de ella; entonces, como nuestro dataset tiene muchas respuestas de 0 affairs, la mediana queda distorsionada. Lo que podemos hacer es pedir calcular este gráfico solo para aquellas respuestas que hayan tenido affairs:
affairs %>%
filter(affairs > 0) %>%
ggplot(aes(x = gender, y = affairs))+
geom_boxplot()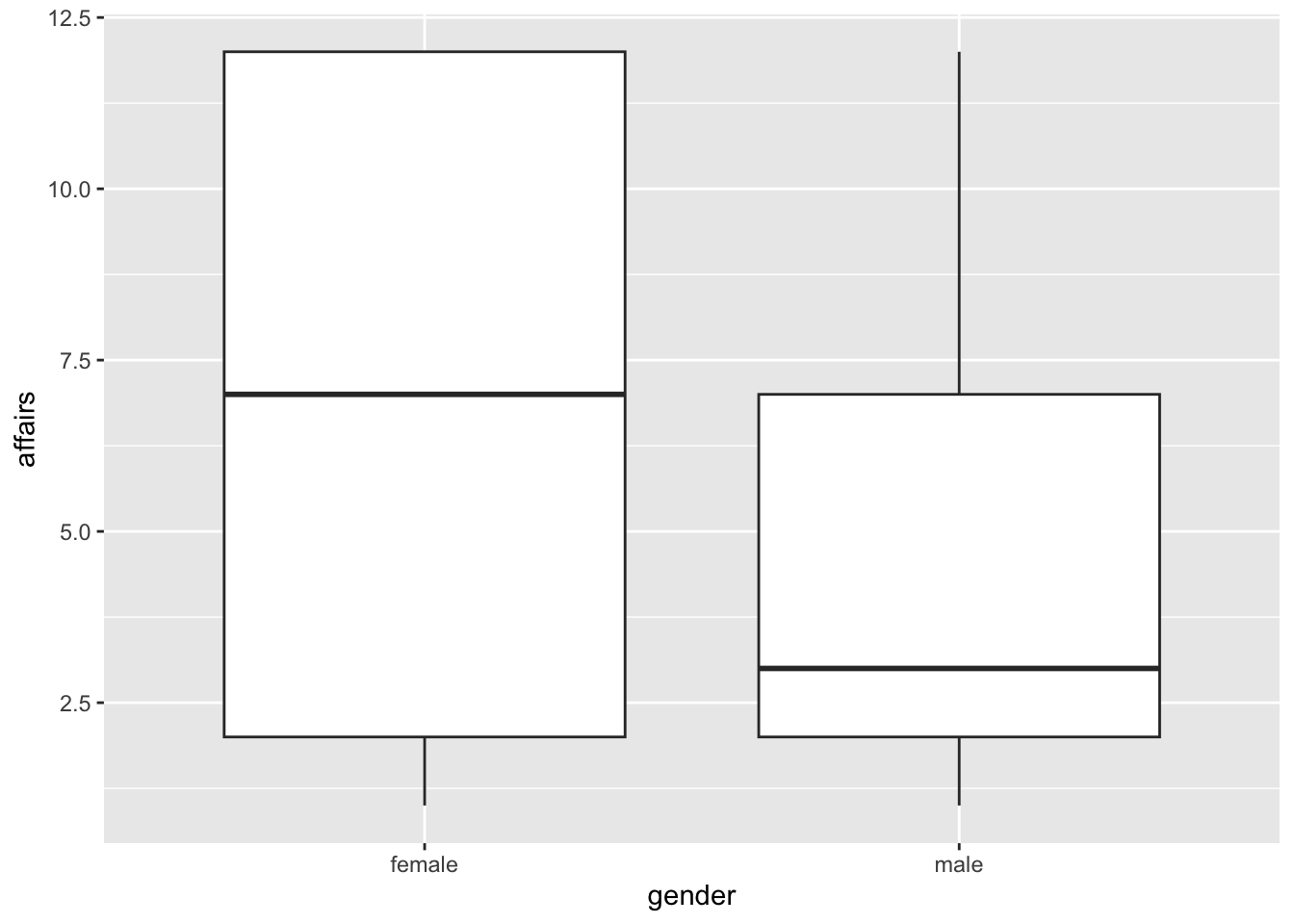
Ahora sí. De hecho, este gráfico nos nuestra que la mediana de cantidad de affairs es más alta para las mujeres que para los hombres, lo opuesto a lo que habíamos encontrado en nuestro gráfico de medias. Esto es porque en ese momento no habíamos caído en la cuenta del efecto de las respuestas de 0 affairs (y recuerden que las medias son muy sensibles a valores extremos), así que los invito a rehacer ese gráfico seleccionando solamente aquellas respuestas que tuvieran affairs.
Hasta ahora estuvimos analizando una y dos variables, y podemos incorporar una tercera:
Pregunta 4: ¿cuántos affairs tuvieron las personas en los diferentes grados de religiosidad, desagregando entre hombres y mujeres?
Aquí tenemos que preguntarnos qué variable queremos que esté en el eje X, cuál queremos que esté en el eje Y, y cuál va a ser la variable de agrupación (es decir, la tercera variable). Vamos a retomar el gráfico de medias, con el grado de religiosidad en el eje X y el género como variable de agrupación:
ggplot(affairs, aes(x = religiousness, y = affairs, color = gender))+
geom_point(stat = "summary", fun = "mean", position = position_dodge(.5))+
stat_summary(fun.data = "mean_se", geom = "errorbar",
width = .2, position = position_dodge(.5))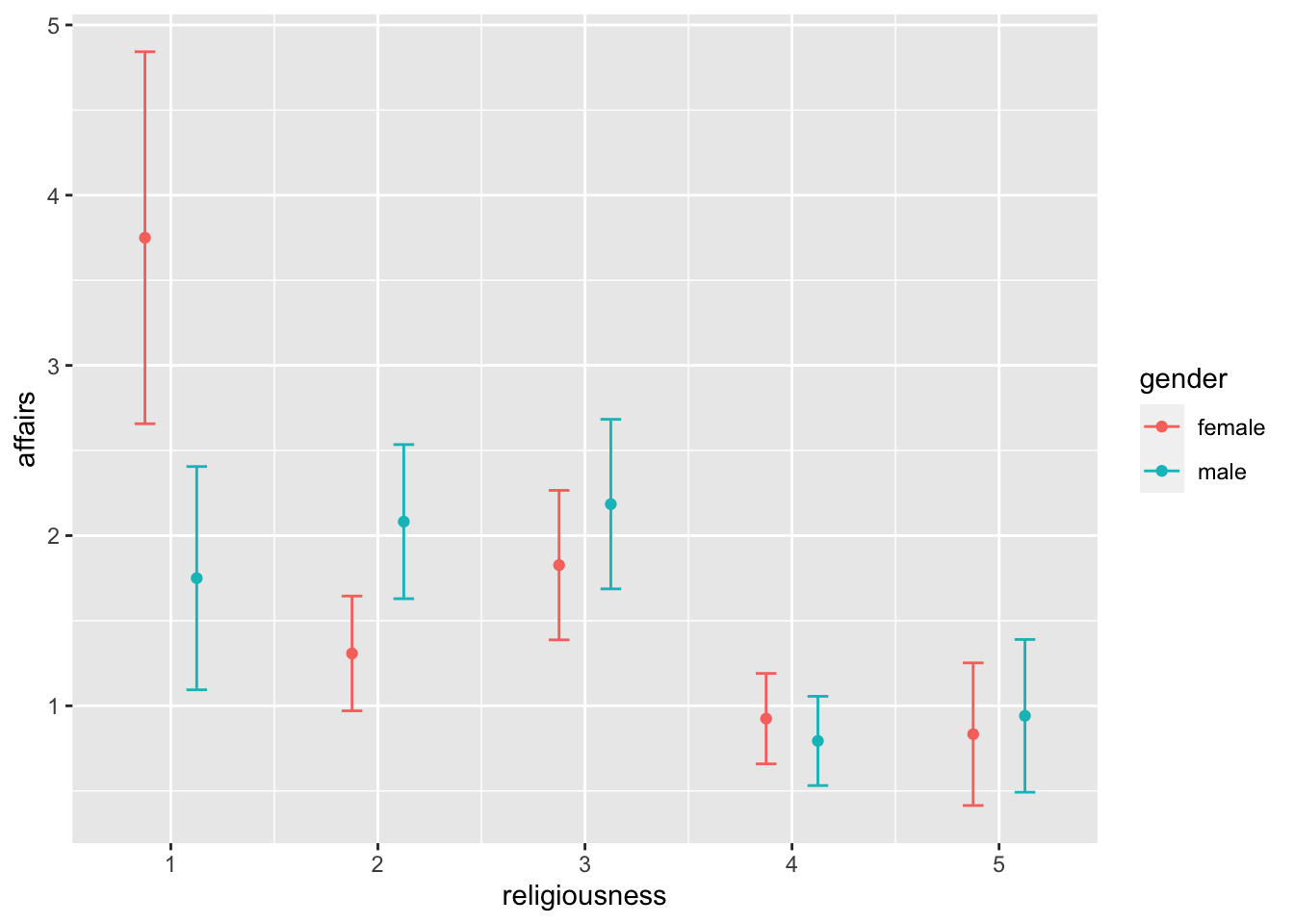
Esto mismo se puede realizar con las otras variables grupales del dataset, ya sean categóricas u ordinales: edad, años de casados, educación, ocupación. Y vamos a ver la forma de agregar una cuarta variable en cuestión a este gráfico:
Pregunta 5: estas diferencias en la cantidad de affairs entre hombres y mujeres de distintos grados de religiosidad, ¿se mantiene cuando los separamos entre quienes tienen hijos y quienes no?
Hay varias formas de incorporar cuatro variables en un mismo gráfico (por ejemplo, se podría hacer un gráfico de dispersión con colores para el género y forma del punto para la diferencia en hijos), pero es posible que se vuelvan difíciles de leer. En estos casos, mi propuesta es separar los gráficos en partes, lo que se llama un gráfico con facetas.
ggplot(affairs, aes(x = religiousness, y = affairs, color = gender))+
geom_point(stat = "summary", fun = "mean", position = position_dodge(.5))+
stat_summary(fun.data = "mean_se", geom = "errorbar",
width = .2, position = position_dodge(.5))+
facet_wrap(~children)
Esto se puede hacer con cualquier variable categórica, pero en general es preferible usar variables con pocos niveles (aquí tenemos solo dos: sí/no), porque si creamos muchas facetas es posible que queden pocos datos en cada una. Podríamos incluso invertir el género y los hijos:
ggplot(affairs, aes(x = religiousness, y = affairs, color = children))+
geom_point(stat = "summary", fun = "mean", position = position_dodge(.5))+
stat_summary(fun.data = "mean_se", geom = "errorbar",
width = .2, position = position_dodge(.5))+
facet_wrap(~gender)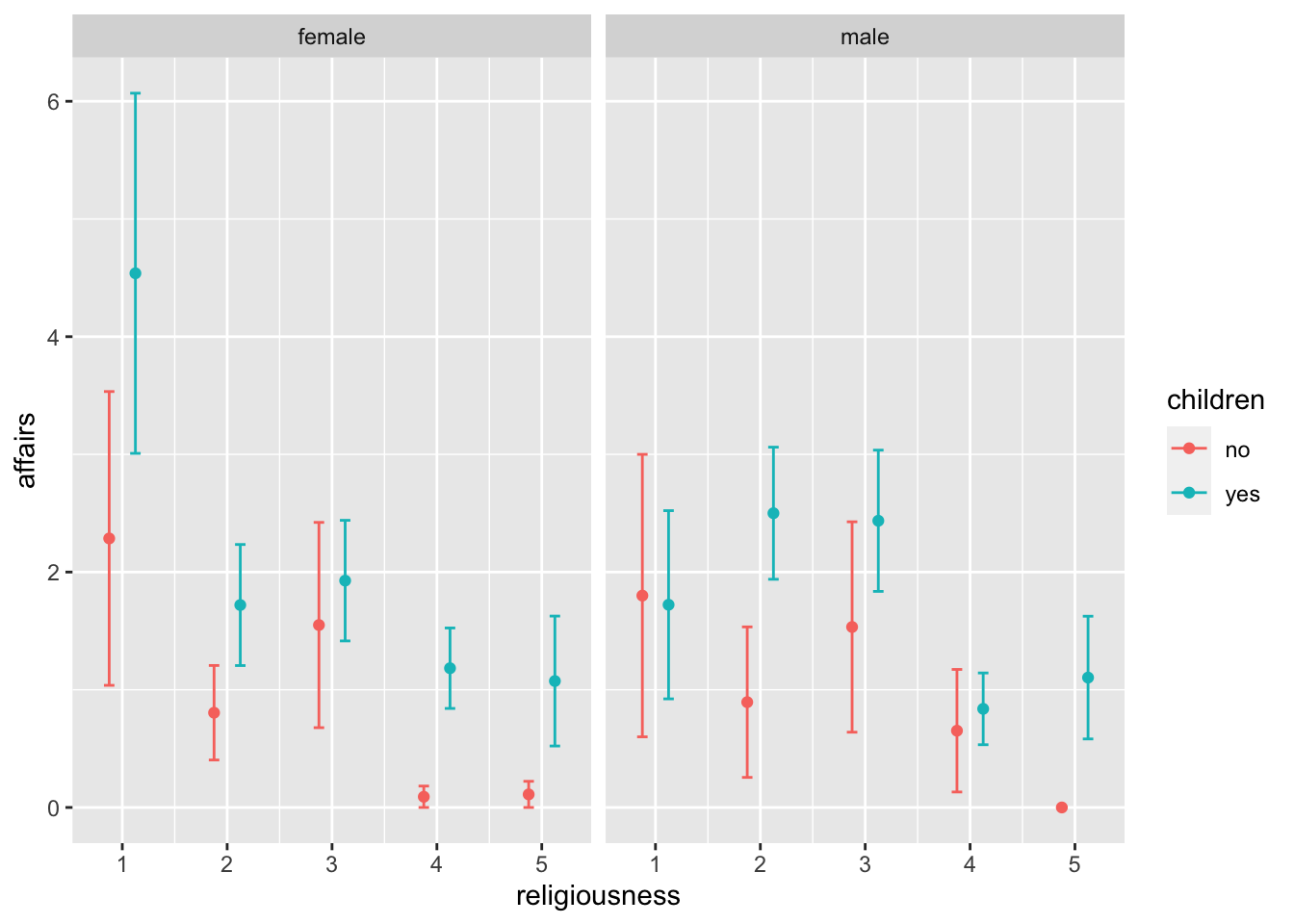
La información es la misma, pero tal vez sirve, en función de nuestra investigación, para pensar distintos tipos de preguntas. Estos gráficos podrían mejorarse incorporando el texto de referencia (títulos, ejes) y una tabla que aclare qué significa cada uno de los niveles de religiosidad (se podrían cambiar los nombres de los niveles en el eje X, pero eso quizá quede muy apretado).
Cierre
Vimos entonces algunas preguntas de investigación y los gráficos asociados a ellas. Usamos los gráficos como herramientas exploratorias para empezar a conocer los datos y propusimos aspectos para mejorar la claridad de la información. Podés jugar a elegir otras variables para realizar los mismos gráficos.
Como siempre, recordá que podés suscribirte a mi blog para no perderte ninguna actualización, y si tenés alguna pregunta, no dudes en contactarme. Y si te gusta lo que hago, puedes invitarme a tomar un cafecito desde Argentina o un kofi desde otros países.
Macarena Quiroga
Lingüista/Becaria doctoral
Investigo la adquisición del lenguaje. Estudio estadística y ciencia de datos con R/Rstudio. Si te gusta lo que hago, podés invitarme un cafecito desde Argentina, o un kofi desde otros países. Suscribite a mi blog aquí.