Cómo hacer una prueba T de Student para comparar dos grupos
En este tutorial vamos a ver cómo hacer una prueba T de Student, teniendo en cuenta sus supuestos, y cómo debe ser reportada en un artículo científico.
 Imagen creada por mí con el paquete {aRtsy}
Imagen creada por mí con el paquete {aRtsy}Introducción: ¿qué es la prueba T?
La prueba t de Student es una técnica estadística que sirve para comparar las medias de dos grupos y determinar si existen diferencias significativas entre ellas. Por ejemplo, si queremos saber si un determinado curso en una escuela tuvo notas significativamente más altas que otro curso. En pocas, poquísimas palabras (recuerden que este no es un blog de estadística), podemos decir que la prueba T evalúa si la diferencia que existe entre medias de los grupos es más grande que la variabilidad intra-grupo.
La prueba T es una prueba paramétrica, lo cual implica que se deben cumplir tres supuestos: las muestras deben ser independientes (es decir, que no haya elementos de un grupo que pertenezcan o influencien a los elementos del otro grupo), deben tener una distribución normal y deben ser homocedásticas (es decir, debe haber igualdad de varianzas). En el caso de que las muestras sean heterocedásticas, es decir, que tengan varianzas distintas, se puede utilizar el estadístico de Welch para muestras apareadas. Si más supuestos se incumplen, se debería evaluar utilizar técnicas no paramétricas, como la U de Mann-Whitney.
Ahora que ya sabemos más o menos qué es la prueba de comparación entre grupos, ¡manos a la obra!
Primer paso: comprobar supuestos
En un post anterior habíamos comenzado a analizar el dataset de pingüinos y habíamos visto que los machos y las hembras tenían un largo del pico distinto. La pregunta que nos podemos hacer es: ¿esa diferencia es estadísticamente significativa?
Empezamos por cargar la base. Si no tenés instalado el paquete datos, borrá el signo # de la primera línea para hacerlo.
install.packages("datos")
library(datos)
pinguinos <- pinguinosEn este dataset tenemos pingüinos de tres especies distintas y de tres islas distintas. Considerando la posibilidad de que la especie tenga un impacto en el largo del pico y que, en consecuencia, dificulte el análisis, vamos a quedarnos solamente con los pingüinos de la primera especie, Adelia. Más adelante vamos a ver cómo analizar el impacto de distintas variables independientes (spoiler: con regresiones). Entonces, segmentemos la base para quedarnos solamente con los pingüinos de la especie Adelia:
ping_adelia <- subset(pinguinos, especie == "Adelia")La función subset nos permite seleccionar una base de datos (pinguinos, el primer argumento) y recortar solamente aquellas filas que cumplan con la condición dada, en este caso, que la especie sea equivalente a “Adelia” (atención con el operador de equivalencia ==, doble igual; podés revisar los operadores básicos en este post). Y ese segmento lo guardamos en un nuevo objeto, llamado ping_adelia, con el operador de asignación <-. Es muy importante que chequees que en el Environment (panel de arriba a la derecha, si no los modificaste) se haya guardado este nuevo objeto.
Empezamos por comprobar el supuesto de muestras independientes: si bien los pingüinos que forman parte de esta muestra pertenecen a la misma especie y coexisten en la misma isla, la asignación “macho” y “hembra” en este caso no es influenciable entre sí, por lo cual podemos asumir que se cumple el supuesto de independencia de muestras.
El segundo supuesto es que la distribución sea normal. Para eso tenemos dos herramientas: el gráfico qqplot y el test de Shapiro-Wilk. Hay varias funciones distintas para graficar un qqplot con distintos paquetes: aquí vamos a usar la función ggqqplot() del paquete ggpubr.
El código para armar un gráfico qqplot sería el siguiente: la primera línea sirve para instalar el paquete (aquí la dejo comentada, pero si no tenés el paquete instalado quitá el # para que se ejecute). La segunda línea carga el paquete (fundamental) y la tercera ejecuta el código. Dentro de la función ggqqplot() tenemos tres argumentos: el primero selecciona el dataframe con el que vamos a trabajar, el segundo selecciona la variable a graficar y el tercero selecciona la variable de agrupación (o mejor dicho de división).
# install.packages("ggpubr)
library(ggpubr)
ggqqplot(ping_adelia, "largo_pico_mm", facet.by = "sexo")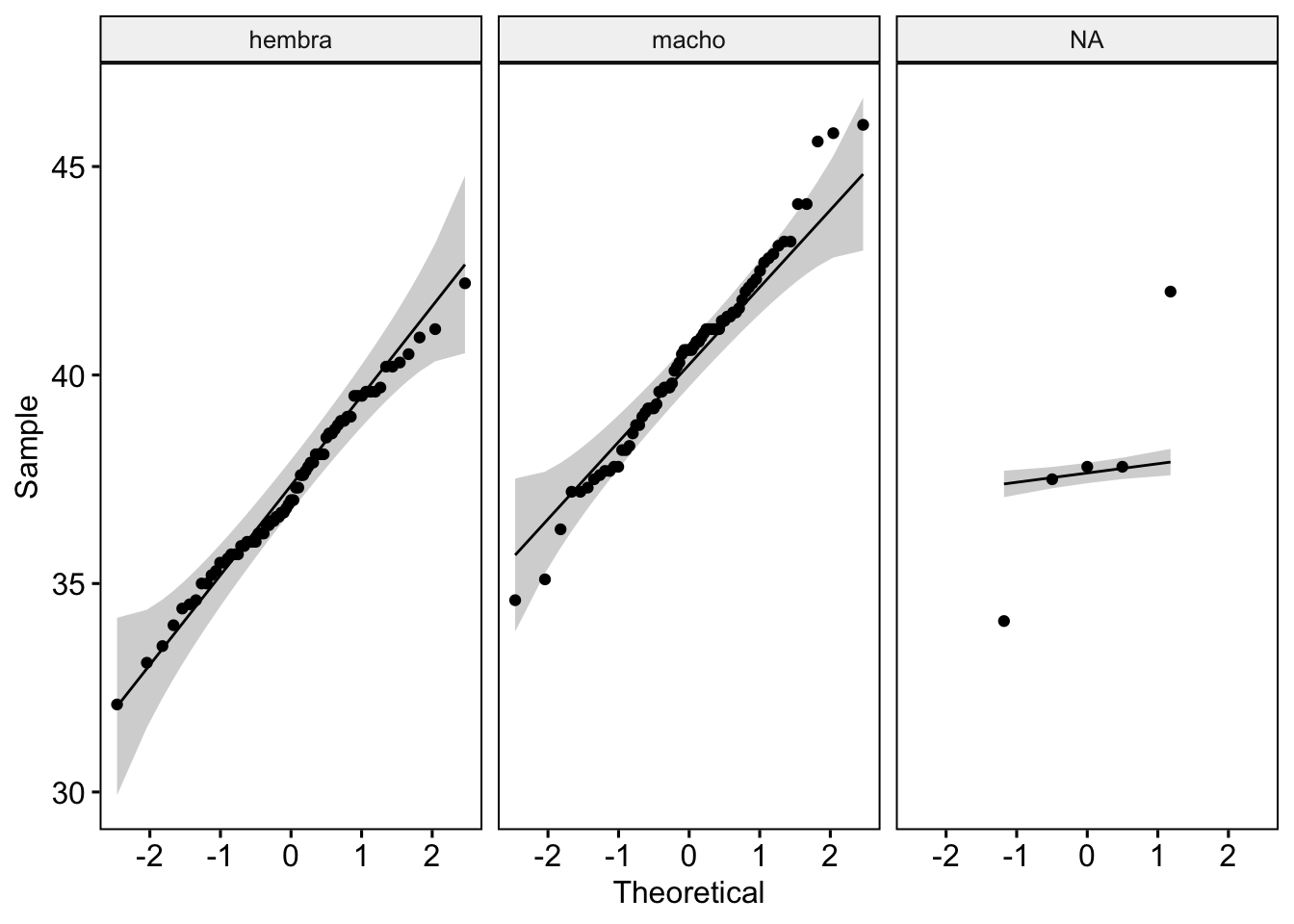
Bueno, acá es donde se pone complicado. La teoría indica que, para que la distribución sea normal, los puntos deben estar todos sobre la línea de referencia, dentro del intervalo de confianza (el sector gris). Si nos pusiéramos puristas, diríamos que hay algunos puntos, sobre todo en los pingüinos macho, que sobresalen de ese intervalo, por lo tanto la muestra no sería normal. Sin embargo, al preguntar a personas especializadas cómo debía leer el gráfico, la mayoría de las respuestas fue que lo miraban a ojo, es decir, a grandes rasgos. Es una respuesta muy poco precisa, lo sé.
Por suerte, tenemos otra herramienta para evaluar normalidad: la prueba de Shapiro-Wilk.
shapiro.test(ping_adelia$largo_pico_mm[ping_adelia$sexo == "macho"])##
## Shapiro-Wilk normality test
##
## data: ping_adelia$largo_pico_mm[ping_adelia$sexo == "macho"]
## W = 0.98613, p-value = 0.6067Si tuviéramos que leer o traducir esa línea de código a lenguaje natural, sería de esta forma: aplicá el test de Shapiro-Wilk (shapiro.test()) sobre la variable largo_pico_mm del dataframe ping_adelia (ping_adelia$largo_pico_mm) para aquellas filas en las cuales el sexo sea macho ([ping_adelia$sexo == "macho"]). Tanto el símbolo pesos ($) como los corchetes ([]) sirven para recortar los dataframes.
Para interpretar el resultado del test tenemos que mirar el valor-p, que en este caso es de 0.6067. Dado que es un valor mayor a 0.05, podemos decir que no podemos rechazar la hipótesis nula (en este caso, la hipótesis nula es que la muestra tiene una distribución normal). Podemos chequear por las dudas qué ocurre con las hembras, aunque el gráfico ya nos mostró que tiene una distribución bastante normal:
shapiro.test(ping_adelia$largo_pico_mm[ping_adelia$sexo == "hembra"])##
## Shapiro-Wilk normality test
##
## data: ping_adelia$largo_pico_mm[ping_adelia$sexo == "hembra"]
## W = 0.99117, p-value = 0.8952Bien, entonces ya tenemos nuestro segundo supuesto confirmado: las muestras tienen una distribución normal. Solo nos queda testear el tercer supuesto: la homocedasticidad de varianzas. Para eso, usamos el test de Levene, dentro del paquete car:
library(car)## Loading required package: carDataleveneTest(largo_pico_mm ~ sexo, data = ping_adelia)## Levene's Test for Homogeneity of Variance (center = median)
## Df F value Pr(>F)
## group 1 0.1744 0.6768
## 144Dentro de la función tenemos en primer lugar la fórmula (largo_pico_mm ~ sexo) y luego el dataframe a utilizar (data = ping_adelia). La fórmula siempre va a tener la misma estructura: primero la variable dependiente y luego la variable de agrupación. Esta sintaxis se va a repetir para todas aquellas funciones estadísticas que tengan variables dependientes e independientes o comparaciones entre grupos, así que es importante tenerla clara. El símbolo que los une, ~, se llama virgulilla (fijate dónde está en tu teclado, sino la podés hacer con alt + 126).
Entonces, el resultado del test de Levene, al tener un p-valor mayor a 0.05, nuevamente no rechaza la hipótesis nula de homogeneidad de varianzas. Por lo tanto, se cumple el supuesto de homocedasticidad.
Segundo paso: el test T de Student
Recién ahora podemos efectivamente pasar a usar la prueba T de Student. La sintaxis es muy parecida a la del test de Levene, con la única diferencia que especificamos que las varianzas son iguales (de lo contrario, utilizaría el test de Welch):
t.test(largo_pico_mm ~ sexo, data = ping_adelia, var.equal = T)##
## Two Sample t-test
##
## data: largo_pico_mm by sexo
## t = -8.7765, df = 144, p-value = 4.44e-15
## alternative hypothesis: true difference in means between group hembra and group macho is not equal to 0
## 95 percent confidence interval:
## -3.838435 -2.427319
## sample estimates:
## mean in group hembra mean in group macho
## 37.25753 40.39041El valor-p es 4.44e-15, porque está en notación científica. Podés desactivarla con el siguiente código:
options(scipen = 9999)Y luego volver a ejecutar el código de la T de Student: el resultado del valor-p ahora es de 0.00000000000000444. Dado que es menor a 0.05, podemos decir que es un resultado significativo y que efectivamente hay diferencias en el largo del pico entre los machos y las hembras de los pingüinos Adelia. La forma de reportarlo en un artículo académico es la siguiente:
La prueba T de Student arrojó diferencias estadísticamente significativas entre los machos y las hembras de los pingüinos Adelia (t(144)=-8.77, p<0.05).
Cierre
En este post vimos cómo evaluar los supuestos necesarios para correr una prueba T de Student que permite comparar entre dos grupos, también vimos la sintaxis para ejecutar esa prueba y el modo de reportar los resultados en un artículo científico. Esta prueba sirve solamente para comparar entre dos grupos: si tenés más de dos (por ejemplo, si quisieras saber si el largo del pico cambia en función de las tres especies), tenés que utilizar un ANOVA.
Como siempre, recordá que podés suscribirte a mi blog para no perderte ninguna actualización, y si tenés alguna pregunta, no dudes en contactarme. Y si te gusta lo que hago, puedes invitarme a tomar un cafecito desde Argentina o un kofi desde otros países.
Macarena Quiroga
Lingüista/Becaria doctoral
Investigo la adquisición del lenguaje. Estudio estadística y ciencia de datos con R/Rstudio. Si te gusta lo que hago, podés invitarme un cafecito desde Argentina, o un kofi desde otros países. Suscribite a mi blog aquí.